








Building a real-time data pipeline using Spark Streaming and Kafka
Building a real-time data pipeline using Spark Streaming and Kafka
In one of our previous blogs, Aashish gave us a high-level overview of data ingestion with Hadoop Yarn, Spark, and Kafka. Now it's time to take a plunge and delve deeper into the process of building a real-time data ingestion pipeline. To do that, there are multiple technologies that you can use to write your own Spark streaming applications, like Java, Python, Scala, and so on.
From the CEO’s Desk: DevOps with Microsoft Azure
DevOps with Microsoft Azure
Last week, the mighty Zeus of the tech world hit the open source world with a lightning bolt. Yes, you guessed it right, I am talking about the GitHub acquisition by Microsoft. The deal, which is worth US$ 7.5 billion, saw Microsoft taking over the distributed version-control platform with more than 28 million active users and 57 million repositories. But why have I become an M&A enthusiast all sudden?
Data ingestion with Hadoop Yarn, Spark, and Kafka
Data ingestion with Hadoop Yarn, Spark, and Kafka
As technology is evolving, introducing newer and better solutions to ease our day-to-day hustle, a huge amount of data is generated from these different solutions in different formats like sensors, logs, and databases. The amount of data being generated is only going one way that is up which means increasing the requirement for storing this humongous amount of data.
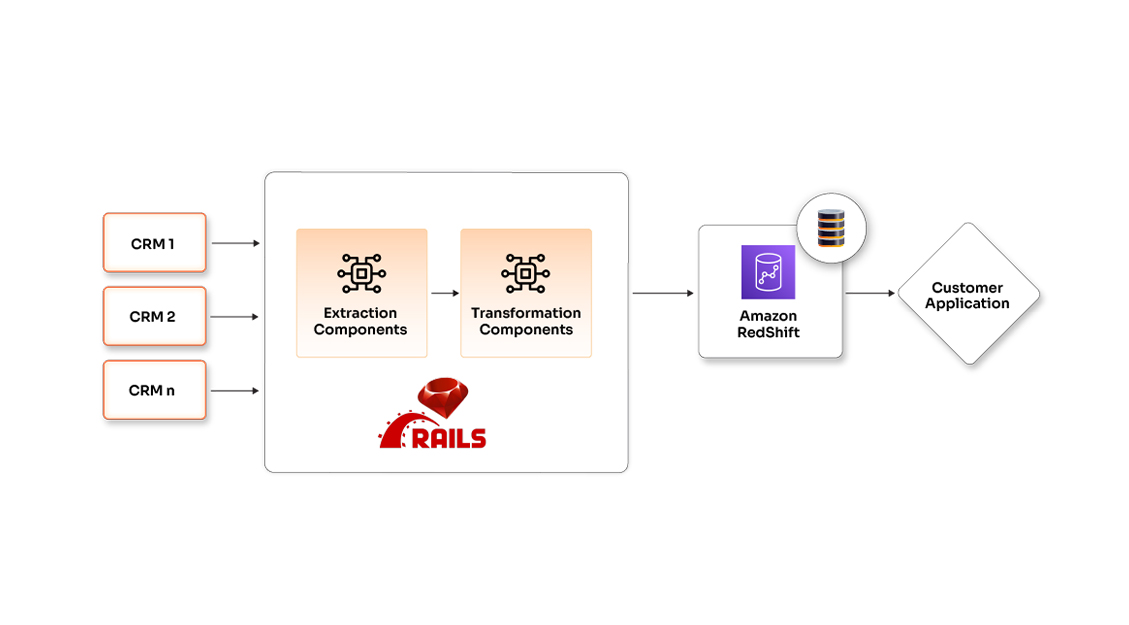
Multi-CRM integration using microservices and ETL automation for marketing automation platforms
Please fill in the following details to read more
See how Opcito achieved multi-CRM integration using microservices and ETL automation for marketing automation platforms
Engagement details
Integrating multiple data streams can be a complicated and tiresome process. Once the integration part is completed, normalizing the information, extracting useful insights from it, and tracking the information source after aggregation can be a hectic process. Above this, adding a new data module can become a tedious and time-consuming process. One has to go through the normalizing and aggregation process every time a new data module is to be added.
Technologies
- Cloud
- Big Data
Tools and platforms
- Ruby on Rails
- Amazon RedShift
Benefits
- Optimized performance and resource utilization
- Simplified operations and reduced time for addition of new data module
Subscribe to our feed
Highlights of the AWS Summit Mumbai 2018
Highlights of the AWS Summit Mumbai 2018
The AWS Global Summit-athon 2018 kicked off earlier this year in March, with the first summit in Tel Aviv, Israel, on 14th March 2018. So far, 9 such summits out of the planned 35 have been successfully completed with a major turnout across the globe from AWS neophytes as well as devouts alike. The AWS Summit Mumbai was the latest one to conclude recently on 10th May 2018, and no wonder, it too was well received with a similar response with overcrowded auditoriums for all events and breakout sessions.
Configuring an Office JS word add-in with ReactJS without the Yeoman generator
Configuring an Office JS word add-in with ReactJS without the Yeoman generator
“Every once in a while, a new technology, an old problem and a big idea turn into an innovation.”
– Dean Kamen, Inventor of Segway
Accelerated data exchange and authentication using ReactJS and JWT

Please fill in the following details to read more
See how Opcito accelerated data exchange and authentication using ReactJS and JWT
Engagement details
A two-part product with a UI part that uses Rails, a server-side web application framework written in Ruby, communicates with the API side through a communication layer and uses a basic authentication system layer with an additional layer for security. The existing system with the additional checks resulted in increased time to process the request by end-user through the API as the requests and responses had to pass through the additional checks, and the Ruby interface was slowing the performance.
Technologies
- React JS
- JWT
- Ruby on Rails
Benefits
- Reduced response time
- Improved user experience
- Enhanced security with JWT framework
Subscribe to our feed
From the CEO’s Desk: Deciphering containerd
Deciphering containerd
Ever since the ascent of containers, Docker has been valued as the most preferred container management tool. But as the technology evolved, the industry players realized that there was a need for customization in the Docker architecture to allow vendors to build things their way. The Docker team has been constantly trying to evolve its offerings to make the platform more composable so that individual components can be spun off and used by other vendors developing alternative solutions.
How to make your application highly scalable and highly available with Corosync and DRBD file sync?
High-Availability Cluster is a group of computers with the purpose of increasing the uptime of services by making sure that a failed machine is automatically and quickly replaced by a different machine with little service disruption.
In this blog, I will explain how you can set up a Jenkins High Availability (HA) cluster using the data replication software DRBD and the cluster manager Heartbeat. In this example, the two machines building the cluster run on Ubuntu 16.04. I will also talk about how to switch between the active and passive machines in case of failover.
Microservices simplified with NGINX app server platform
Microservices simplified with NGINX app server platform
NGINX, a project started in 2002, is now a company widely appreciated for its open-source web-server platform which is rivaling the likes of Apache and Microsoft. With its position firm in the web-server space and an ever-increasing market share, NGINX is now coming up with an arsenal of enhancements to bolster its application platform technology. A lot of us are moving from monolith to microservices, and NGINX is always encouraging organizations the adoption of microservices architecture.