













FOR SRE?
We have established ourselves as pioneers in the industry, working with leading organizations of all sizes. Our experience over the years has led to setting up robust processes and techniques for SRE. We conduct an end-to-end assessment of your platform & tools and ensure your infrastructure is secure and highly functional. Our monitoring and incident management expertise ensures that your systems always function to their best capacity and that you experience zero downtime. Opcito's SRE engineers follow standardized protocols and processes to monitor & fix errors, ensuring reliable and highly scalable software solutions.
GUARANTEES
SRE offers clarity by monitoring and measuring the occurrence of bugs, service health, efficiency, and productivity. This is used for measuring tangible elements like average downtime and its impact on lost revenue due to downtime. SREs use these metrics to find better solutions to problems and prevent bugs and other issues in the future.
SRE engineers focus on finding the best ways to modernize workflows through automation. They also detect bugs & vulnerabilities and continuously improve their workflow. Increased automation and using machine learning to identify & fix bugs lead to an improved level of reliability of services and systems.
Rapid product development undoubtedly helps you stay ahead of the competition, but also invites problems like bugs and software vulnerabilities. SRE solves these issues by practicing proactive troubleshooting and detecting issues at an early stage. Early issue detection boosts the reliability of the product, ensuring happy customers.
Monitoring helps developers resolve potential issues in advance and focus more on developing new features instead of firefighting. Simply put, a reliable system enables developers to spend more time building new features to create more value for end-users.
SREs always focus on the customer and meeting their expectations. This is achieved by relying on metrics like SLA, SLI, and SLO, which boost reliability and ROI.
SRE bridges the gap between development teams and operations teams. We enable site reliability engineers to find ways to improve their communication by implementing and enhancing automation – thereby enabling a better sync between different groups.
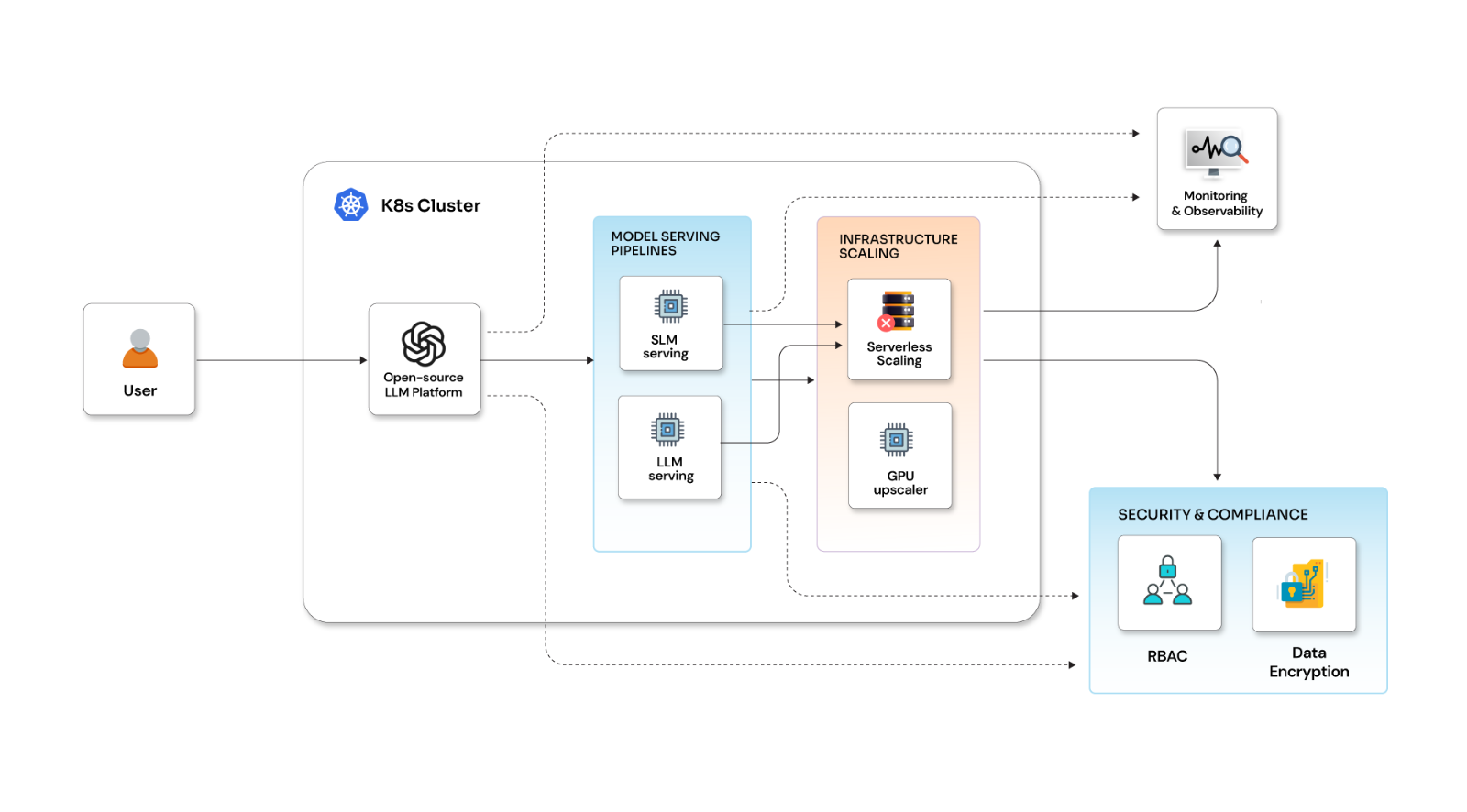
SRE Services

End-to-end assessment of existing systems, tools, platforms, environments, and practices to design a concrete plan with capacity planning, resource allocation, automation, measurable SLIs & SLOs, incident management processes, automated runbooks, and processes that can be standardized.
Management
Eliminate common production incidents with a robust CI/CD pipeline for your DevOps SRE initiatives with the right tools and cloud-native approach that is secured, auto-scalable, and fault-tolerant with a self-healing infrastructure and application management system using change management and advanced analytics.

Incident Response
Solutions
Real-time data analysis and proactive, automated monitoring of cloud, VMs, and containers to monitor Infrastructure health and detect issues in real-time, combined with a preemptive incident management system designed using pre-populated diagnostics and an automated step-by-step resolution guide.

Assessment
Audit incidents & incident response to ensure minimal risks in the future. We learn from these incidents to build more robust solutions and processes to mitigate future shortcomings. Identifying the root cause of issues helps understand the impact, avoid incidents, and improve incident response in the future.

Support
Operate confidently with Opcito's SRE engineers with expertise in DevOps, Containers, Kubernetes, Cloud, and Chaos engineering that support you in standardizing and automating set procedures to manage routine tasks, standard incident response practices, and reliability monitoring.