














Posted By

Data migration may conceptually sound simple, but it is one of those things that are not as simple as they sound. This is especially true in the context of Cloud Migration, where complexities can multiply. The lack of integration and synchronization between system components may lead to the loss or corruption of critical data. It may also lead to data quality issues along with security challenges which may incur heavy financial and reputational risks. Moreover, recovering data is an extremely tedious, time-consuming, and costly affair. And even after going through all this, the data needs to be checked and validated, resulting in extended downtimes. Considering the burnout, security challenges, and data quality issues involved in data migration, most organizations treat data migration as a distinct project, often leveraging expertise in Data Engineering to navigate these complexities. This blog is about how we addressed the exact problem for one of our clients with the help of ES Index Migration. But before we start with the actual solution for your migration needs, let me tell you in brief about ES Index and ES Index Migration.
What is ES Index?
An Index is usually a set of one or more Documents, whereas a Document encompasses one or more fields. While referring to databases, a table row is termed a Document, and a table column is termed as a Field. An Index is like a database within a relational database and has mapping defining multiple types. It is a logical namespace that maps one or more primary shards and can have zero or more replica shards. Elasticsearch can fast search responses as it searches an Index instead of searching the text directly. This is like retrieving pages in a book related to a keyword by scanning the Index at the back of a book, instead of searching every word on every page of the book.
What is ES Index Migration?
Imagine a scenario where you want to migrate production Elasticsearch data to staging for QA purposes. There could be a lot of scenarios, such as:
- Upgrading underlying cloud infrastructure/instance types for ES deployment
- Migrating from one cloud to another cloud
- Migrating from on-premises to cloud or vice versa
- Creating a pre-prod/staging environment from production data clusters
Here you may want to migrate Indices/data from one Elasticsearch cluster to another Elasticsearch cluster.
You can migrate ES Indices via the following ways:
- Index your data from the original source
- Reindex from a remote cluster
- Restore from a snapshot
To ease out this operation, we created a simple Python-based automation tool that can migrate data from one Elasticsearch database to another using S3-based snapshot.
Prerequisite
To migrate using an S3-based snapshot, both clusters need to install the given plugin:
sudo bin/elasticsearch-plugin install repository-s3 https://www.elastic.co/guide/en/elasticsearch/plugins/current/repository-s3.html
Here is how it works:
- Clone the following Repo on your machine:
$> git clone https://github.com/sachingade20/elasticsearch_migrator.git $> cd elasticsearch_migrator $> pip install -r requirements.txt
- Update migration.yml with required config values:
source_es_host: dest_es_host: source_es_port: 9200 dest_es_port: 9200 bucket_name: aws_region: indices_list: indices1,indices2
- Run migration utility:
$ python migrate_utility.py
How it migrates?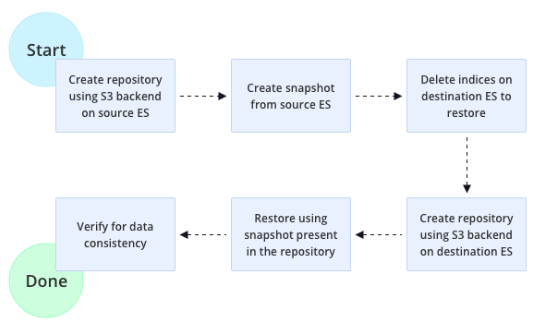
That was a brief overview of how the tool works and how it takes care of data migration projects. It is clear from the above explanation that the tool interacts with three components in the environment: the source database, the destination database, and the storage element that acts as a medium between these two databases. The whole purpose is to achieve data migration in the most simple and efficient way. I hope this simplifies the Index migration process for your Elasticsearch. For more on optimizing your IT operations with Elasticsearch, check out our blog on Optimizing IT Operations with Elasticsearch Machine Learning.





