














Posted By

In our previous blog, "Vector Databases: Revolutionizing AI and Search," we explored how vector databases transform the handling of complex data. From powering semantic search engines to enabling personalized recommendations, vector databases have emerged as a cornerstone of modern AI-driven applications. If you haven't read it yet, you can read it here.
Now, let's delve deeper. In this blog, we'll explore the technical aspects behind vector databases and how they store, index, and retrieve high-dimensional vectors at lightning speed. We'll also examine the cutting-edge technologies that make them efficient, from embeddings and Approximate Nearest Neighbor (ANN) search to dimensionality reduction and distributed computing.
Why vectors, and why now?
In modern AI-driven applications, data—whether text, images, or audio—is converted into vectors, which are numerical representations that capture the essence of the data. Think of vectors as a way to translate complex information into a language machines can understand. By representing data in a high-dimensional space, vectors preserve relationships between objects, enabling tasks like answering questions, translating languages, and understanding context.
For example, in Natural Language Processing (NLP), models like Word2Vec, GloVe, and BERT transform words and sentences into vectors, capturing their meaning and relationships. This is how machines can "understand" language and perform tasks like search, recommendations, and more.
What are the key techniques behind vector databases?
Vector databases rely on advanced technologies to enable real-world applications. Here are the key components that make them work:
- Embeddings and feature extraction: Embeddings transform raw data—such as text, images, and audio—into multi-dimensional vectors that capture their semantic meanings. Natural language processing models like Word2Vec and BERT create embeddings that enable AI systems to analyze and compare data based on context.

- Approximate Nearest Neighbor (ANN) search: ANN algorithms, including FAISS and HNSW, facilitate rapid similarity searches within large datasets by minimizing computational demands. For instance, Facebook employs FAISS to effectively find similar images or user profiles with high efficiency.
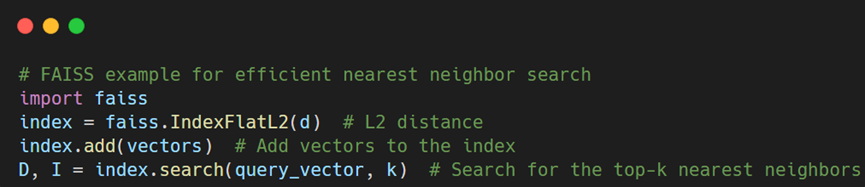
- Dimensionality reduction: Techniques such as Principal Component Analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE) help reduce the dimensions of vectors while maintaining essential features. This approach accelerates searches without compromising accuracy, making it particularly beneficial in image recognition tasks where vectors may contain hundreds of dimensions.
- Indexing structures for fast retrieval: Advanced indexing techniques like HNSW organize vectors to allow for real-time retrieval. This capability supports applications such as product recommendations that respond promptly to user queries.

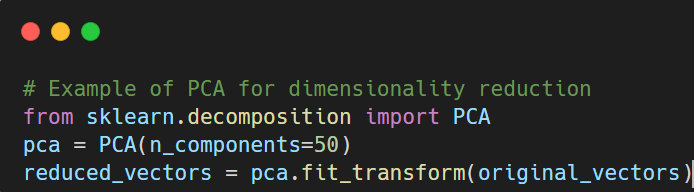
- Vector similarity metrics: Metrics such as cosine similarity and Euclidean distance gauge the proximity of vectors. This measurement is crucial for semantic search engines that retrieve information based on meaning rather than exact matches.
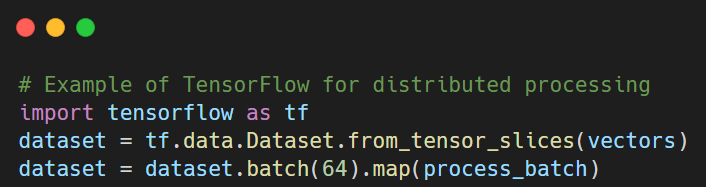
- Distributed computing and parallel processing: Apache Spark and TensorFlow frameworks empower parallel processing, providing scalability and responsiveness even when handling massive datasets.
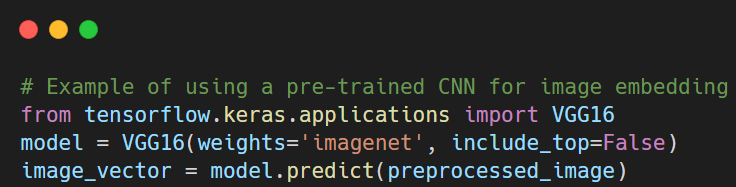
- Deep learning models for vector generation: Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) generate vectors representing data features. These vectors are key in tasks such as image searches (CNNs) and sequence analysis (RNNs).
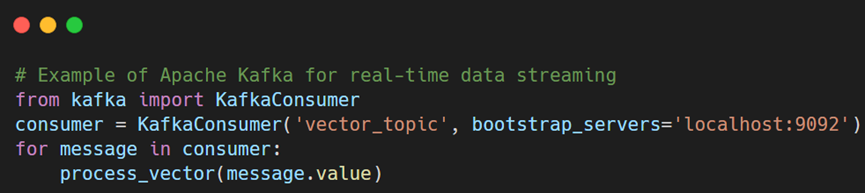
- Real-time data processing: Technologies like Apache Kafka and Flink are designed to manage live data streams, allowing instantaneous updates and searches. This capability is essential in applications like fraud detection.
- Cloud integration and scalability: Cloud platforms such as AWS and Azure offer on-demand scalability, which powers systems like Amazon's recommendation engine and supports Google's various AI services.

These techniques are fundamental to modern vector databases, facilitating efficient, scalable, and intelligent data management across various industries.
What are the applications of vector databases in UI and backend apps?
Vector databases power a wide range of applications across UI and backend systems:
- Enhanced search functionality in UI: Vector databases enable semantic search by converting user queries into vectors and retrieving results based on meaning, not just keywords. For example, a query like "best coffee shop in Paris" returns contextually relevant results even without exact keyword matches.
Example:
- Personalized recommendations in E-commerce and media: These systems store user preferences as vectors and compare them with product vectors to suggest tailored content. Platforms like Netflix and Spotify use this technology to deliver personalized recommendations that improve user engagement and satisfaction.
Example:
- Image and visual search in front-end applications: Vector databases allow users to search for visually similar images by converting images into vectors. This technology is widely used in e-commerce platforms and stock photography websites to enhance product discovery.
Example:
- Real-time fraud detection in backend systems: By converting transaction data into vectors and comparing them to known patterns, vector databases can detect anomalies and flag suspicious activity in real-time, significantly improving security measures in financial systems.
Example:
- Chatbot and virtual assistant intelligence: Vector databases improve conversational AI by converting user queries into vectors and retrieving contextually relevant responses, making interactions more natural and effective.
Example: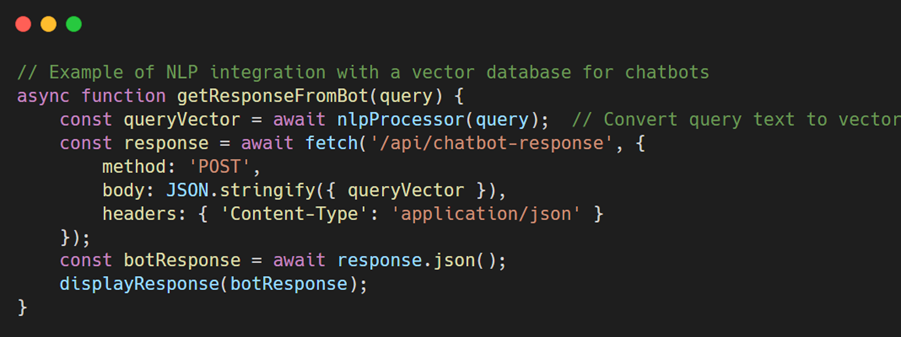
- Document search and information retrieval in backend: These systems retrieve documents based on semantic similarity rather than just keywords, enhancing knowledge bases and enterprise search engines with more relevant results.
Example:
- Multimodal search in backend systems: Vector databases combine text, image, and video search by representing all data types as vectors, enabling powerful cross-medium retrieval capabilities.
Example: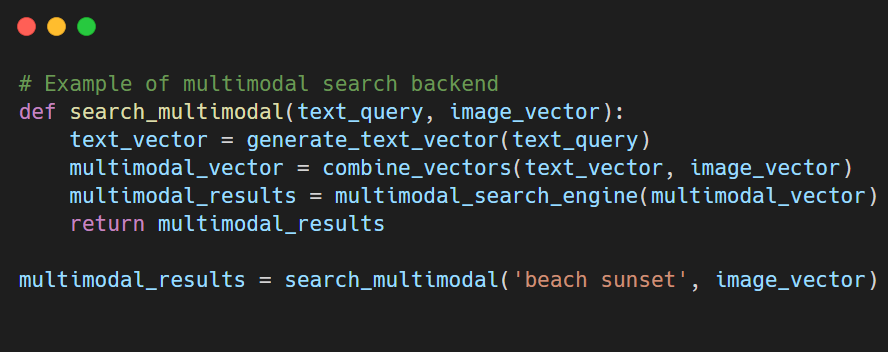
- Speech recognition and voice command processing: These systems process spoken commands by converting speech into vectors and matching them with stored command vectors for quick and accurate execution.
Example:
- Backend analytics for customer insights: Vector databases analyze user behavior by comparing activity vectors, helping businesses make data-driven decisions about product development and marketing strategies.
Example: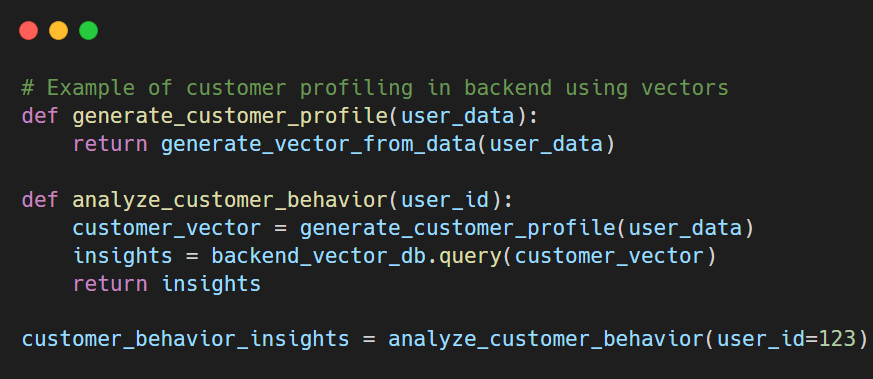
These applications demonstrate how vector databases enable intelligent, context-aware systems across domains like e-commerce, fraud detection, and conversational AI.
Top nine challenges in implementing vector databases in UI
Despite their advantages, implementing vector databases comes with several challenges:
- Scalability issues with large datasets: Handling vast amounts of data in real-time can strain resources. E-commerce platforms like Amazon must scale vector search to handle massive product catalogues while ensuring low latency and relevance, especially during peak traffic periods. This requires robust infrastructure and sophisticated algorithms.
- Complexity in vector generation and embedding models: Converting raw data into meaningful vectors requires advanced models like BERT or ResNet, which demand significant training data and computational resources. Regularly updating these models for better performance adds complexity, particularly in dynamic UI environments.
- User privacy and data security concerns: Vector data can potentially leak sensitive information. Since embeddings represent complex data numerically, they might reveal user behavior or preferences, posing privacy risks that must be carefully managed, especially in regulated industries like healthcare.
- Real-time processing and latency: Ensuring low-latency responses is critical for real-time applications. Virtual assistants like Siri or Alexa require instant responses to voice commands, making optimization for fast query times essential for maintaining a positive user experience.
- Integrating vector databases with legacy systems: Legacy systems built on traditional SQL databases are not designed for vector-based technologies. Integrating vector search capabilities requires significant reengineering, which can be particularly challenging for established enterprises with complex IT infrastructure.
- Model drift and maintenance: Embeddings can become outdated as user data and behavior evolve, leading to reduced accuracy. Regular retraining and updates are necessary to keep vector representations aligned with current trends and user preferences.
- High computational requirements for embedding generation: Generating and updating vector embeddings demands significant computational resources, especially for deep learning models. Managing this workload efficiently without compromising performance presents ongoing challenges for organizations.
- Handling data quality and noise: Poor-quality data can lead to inaccurate vectors and suboptimal search or recommendation performance. Effective data cleaning and preprocessing are essential to ensure the quality of vector representations.
- Cost of storage and processing: Storing and processing high-dimensional vectors can be resource-intensive, especially for large-scale systems. Balancing fast retrieval with storage and computational costs requires careful optimization and resource management.
The future of data is vector-powered
Vector databases are revolutionizing how we interact with data, enabling machines to understand context, meaning, and relationships like never before. Yet, challenges like scalability, computational demands, and data quality remain. These aren’t roadblocks—they’re opportunities for innovation. For organizations ready to tackle these challenges, vector databases offer a path to building intelligent, context-aware systems that redefine user experiences. The question isn’t if they’ll become mainstream, but how quickly we can innovate to unlock their full potential.
Stop struggling with vector database implementation. Opcito's vector database experts are ready to transform your AI initiatives from concept to competitive advantage. Contact us to schedule a free strategic assessment with an expert.





