














Posted By
Increasing data volumes are like double-edged swords. The good thing about that is - a lot of data means a lot of information and a lot of value that comes with it. However, it also means a lot of technology to store and analyze this information is on its way. Thankfully, the graph database, with its agility, performance, and flexibility, is here to help us through this.
A graph database uses graph structures with two major elements for semantic queries, viz., nodes and relationships. Nodes are the entities in the graph, and relationships represent the connections between two nodes. In normal databases, data is the most important entity but a graph database treats the relationships between data with equal importance. Instead of narrowing down the approach towards data with a predefined model, the data is analyzed based on the interrelation between two nodes. Let’s take an example that will help you understand what I am talking about. Just to make sure everyone gets it, I will select everyone’s favorite topic.

In this particular example, New England Patriots, Tom Brady, and Greater Boston are the nodes. The relationship between these nodes is represented over the arrow, and the arrow represents that these relationships are directional. The additional attributes associated with the nodes are properties as represented below the node.
Neo4j is open-source and provides an ACID-compliant transactional backend. Neo4j is referred to as a native graph database because of the efficient implementation of the property graph model down to the storage level. This means that the data is stored exactly as you whiteboard it, and the database uses pointers to navigate and traverse the graph. When it comes to production scenarios, Neo4j assures cluster support and runtime failover. Apart from these and the efficient store, process, and raise queries, here are some of the features and advantages that make Neo4j a popular choice among graphical databases -
- It follows the Property Graph Data Model.
- It supports UNIQUE constraints, which ensures the uniqueness of the data stored.
- It contains a UI (Neo4j Data Browser) to execute CQL Commands that help to create and alter different storage unit for data. Neo4j CQL query language commands are in a readable format and very easy to learn.
- The ACID(Atomicity, Consistency, Isolation, and Durability) rules support and ensure the validity of the data.
- Support for Cypher API and Native Java API makes it easy to develop Java applications./li>
- It is very easy to represent and retrieve/navigate connected data as well as it represents semi-structured data very easily.
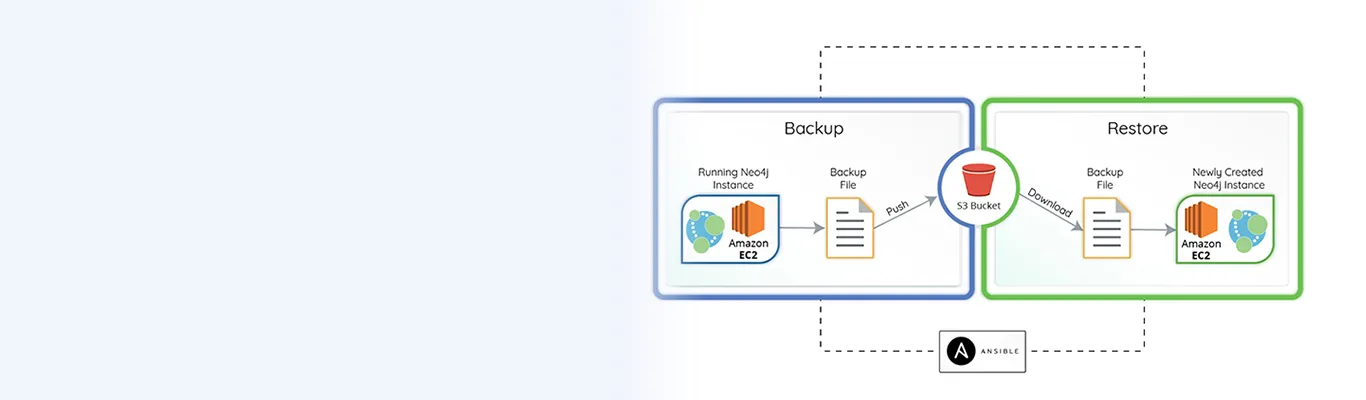
Recently, in one of the projects I was working on, we wanted to automate the Neo4j database backup and restore process. We used Ansible’s configuration management capabilities to automate this Neo4j database Backup and Restore. Ansible is open-source and I love the way it enhances the scalability, consistency, and reliability of any IT environment. You can use Ansible to automate tasks such as - provisioning servers you need in your infrastructure or for configuration management or application deployment.
Now, let us see how the actual backup and restore process is like.
Backup Role
In case of unwanted scenarios like accidental deletion of data or a database instance gone down, to revert to the previous database state, we need to have the latest backup file of the running database. To save the existing Neo4j database, I have created this Backup role that can take a backup of the existing Neo4j instance and push the backup file to the S3 bucket.
Here is an Ansible playbook to take the backup of the Neo4j Database -
--- # tasks file for neo4j_backup - name: Create a neo4j backup file with proper permissions file: path: /var/lib/neo4j/import/ state: touch owner: neo4j group: adm mode: '0644' - name: Copy cypher file on neo4j instance template: src: backup.cypher.j2 dest: /tmp/backup.cypher - name: Taking a backup shell: cat /tmp/backup.cypher | cypher-shell -u neo4j -p neo4j123 - name: install boto packages pip: name: boto botocore boto3 executable: pip-3.3 - name: Copy file to S3 bucket vars: ansible_python_interpreter: /usr/bin/python3 aws_s3:aws_access_key: "" aws_secret_key: "" bucket: neosrc: /var/lib/neo4j/import/ mode: put object: "" environment: PATH: /usr/bin/python3
To execute the backup command in the cypher-shell, I have created a backup.cypher.j2 file in the roles template folder -
backup.cypher.j2
BEGIN
CALL apoc.export.graphml.all('', {useTypes:true, storeNodeIds:false});
:COMMIT
: To back up the existing Neo4j database, I have created the neo4j-backup role. The backup.cypher.j2 file will help to execute the backup command. The task written in the tasks/main.yml file will execute the cypher file with the help of a cat command to log in to the Neo4j database using the database credentials. Once the process is completed, the backup file will get pushed to the specific S3 bucket in AWS.
To execute the Neo4j Backup role, I have created a neo4j-backup.yml playbook -
--- - name: Neo4j-Backup hosts: neo4j gather_facts: true remote_user: ubuntu become: true roles: - neo4j_backup
To run this neo4j-backup role, the following command can be used: ansible-playbook -i inventory neo4j-backup.yml -e AWS_ACCESS_KEY_ID=****************** -e AWS_SECRET_ACCESS_KEY=********************** -e environment_name=poc -vvv
Restore Role
Now that we have a backup file with us, let’s see how to restore your database to the previous state. To restore the Neo4j database, download the latest backup file from the S3 bucket and restore it on the newly created database instance.
Here is an Ansible playbook to restore the Neo4j database -
--- # tasks file for neo4j_restore - name: install boto packages pip: name: boto botocore boto3 executable: pip-3.3 - name: Download file from S3 bucket vars: ansible_python_interpreter: /usr/bin/python3 aws_s3: aws_access_key: "" aws_secret_key: "" bucket: neo4j-backup object: "" dest: /home/ubuntu/ mode: get environment: PATH: /usr/bin/python3 - name: Copy cypher file to restore neo4j database template: src: restore.cypher.j2 dest: /tmp/restore.cypher - name: Restoring Backup shell: cat /tmp/restore.cypher | cypher-shell -u neo4j -p neo4j123
To execute the restore command in the cypher-shell I have created a restore.cypher.j2 file in the roles template folder -
restore.cypher.j2
:BEGIN
CALL apoc.import.graphml('./', {batchSize: 10000, readLabels: true, storeNodeIds: false});
:COMMIT
To restore the backed-up Neo4j database on a new instance, I have created the neo4j-backup role. In this, I have created the restore.cypher.j2 file to execute the backup command. After that, in tasks/main.yml file, I have written the task to execute the cypher file with the help of cat command to log in to the neo4j database using database credentials. To restore the database, you need to pass the backup file that is on the S3 bucket with date and time.
To execute the Neo4j Backup role, I have created a neo4j-backup.yml playbook -
--- - name: Neo4j-Restore hosts: neo4j gather_facts: False remote_user: ubuntu become: true roles: - neo4j_restore
To run this neo4j-restore role, use the following command -
ansible-playbook -i inventory neo4j-restore.yml -e AWS_ACCESS_KEY_ID=************************ -e AWS_SECRET_ACCESS_KEY=******************** -e BACKUP_FILE=neo4j_backup_file.graphml -vvv
Using this backup role you will be able to take the backup from the Neo4j instance and push the backup file to the S3 bucket. Similarly, you can download the backup file pushed to the S3 bucket on the Neo4j instance to restore the Neo4j Database using the restore role. This was a quick rundown of how you can backup and restore Neo4j Database using Ansible. If you have any queries or want to share suggestions to ease the restore and backup process, feel free to comment.





