


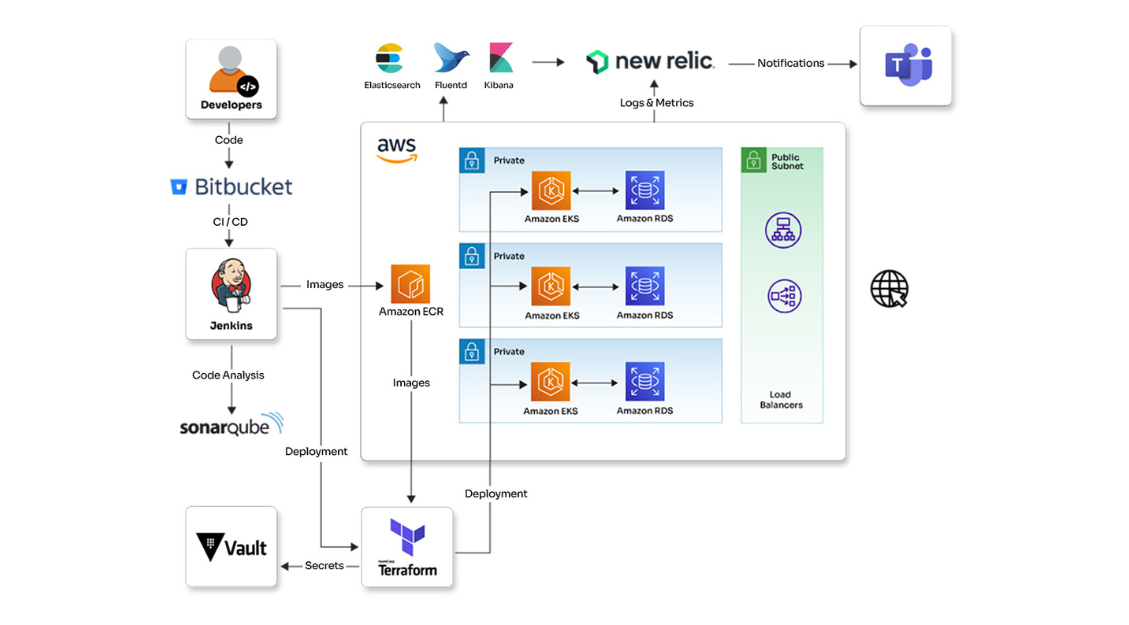






Augmenting your SRE potential with observability
Site Reliability Engineering (SRE) is a discipline that uses software engineering principles to enhance the reliability and scalability of software systems. Originally coined in 2003 by Google’s Ben Sloss, SRE involves automating IT infrastructure reliability tasks, such as system management and application monitoring. It also oversees critical aspects, including availability, performance, latency, efficiency, capacity, and incidence response, to ensure highly dependable software systems. Site reliability engineers replace manual management of numerous aspects with software-driven automation, making system maintenance more sustainable and efficient.
The need for observability
Modern software architecture like microservices, cloud-native architectures, and distributed systems are incredibly complex and traditional monitoring approaches need more timely detection of threats. With such complexity, there is a need for better visibility into the systems to understand the state of every component that resides within it. The threat that distributed and interconnected systems face is that failure in one component can affect the entire system, and pinpointing the problem to rectify it can be tedious and costly.
Observability provides in-depth visibility into all areas of the system so that threats can be mitigated at the earliest. This is possible by monitoring the system's health, tracking changes, and understanding how various users interact.
Components of observability
Observability, in general, is based on three pillars - Metrics, Logs, and Traces. These pillars are the three data types it leverages to analyze system health. Find more information and an in-depth explanation of the three pillars in our previous blog - What is observability and why the buzz? The blog will also help you understand the difference between monitoring and observability.
The role of observability in SRE
Here is how Observability and SRE are interconnected. As Site Reliability Engineering's (SRE) key focus area is maintaining system availability, reliability, and resilience, observability is a handy tool for achieving these goals. SREs work round the clock to gain efficiency and prevent outages by detecting and resolving issues swiftly. Additionally, because it offers insights into system performance and potential architectural flaws, it assists SREs in their mission of maintaining overall system health. We'll further look at the detailed benefits that SREs gain with observable systems.
How does observability benefit SREs
Here's a detailed explanation of why SREs swear by observability.
Early issue detection with root cause analysis: Observability tools and practices provide real-time insights into the health of systems. SREs can use these insights to detect issues and anomalies early, often before they impact users, allowing for proactive problem resolution. SREs value observability because they give visibility into how applications or systems behave at any given time. This insight lets you recognize possible concerns before they become more extensive or expensive, such as service outages. Observability tools offer real-time insights into system health, enabling SREs to detect issues and anomalies proactively, often before they impact users. This proactive approach minimizes the potential for service disruptions. A system's observability allows discovering those conditions that SRE teams had not even considered before (the "unknown unknowns") and correlating them further with specific issues. Observability helps SREs pinpoint the root cause of the problem when something goes wrong. They can examine logs, metrics, and traces to understand the sequence of events leading to the issue, facilitating faster resolution.
Performance optimization: When systems are distributed, tracking the performance indicators, and measuring system performance is tricky. Observability data helps SRE teams overcome these challenges by giving them real-time system visibility. Once there is clear visibility and a deep understanding of the systems, it becomes easy to identify underperforming areas, bottlenecks, and other performance issues to optimize them. It also helps teams proactively fix issues that could escalate into major problems. This helps them maintain the desired service quality and efficiency level while sticking to their development cycle timelines.
Capacity planning: SREs must guarantee that systems can adequately handle incoming traffic and demand. This means that the SRE must determine the service's initial resource needs and ensure it remains stable even during unexpected demand. Here, observability data helps in three ways. Firstly, SREs can investigate current and historical data related to the usage of IT resources like memory, disk space, CPU, and network bandwidth. This data showcases trends that can be useful for making future analysis. Secondly, based on the forecasted trends, SREs can plan to size resources like CPU, memory, network bandwidth, and disk space. Lastly, once the resource needs are determined, SREs can ensure they are readily available. This involves provisioning cloud resources & servers, upgrading hardware, and optimizing software to meet future needs more efficiently, helping SREs plan capacity.
Monitoring Service Level Objectives (SLOs): SREs must guarantee that systems can adequately handle incoming traffic and demand. This means that the SRE must determine the service's initial resource needs and ensure it remains stable even during unexpected demand. Here, observability data helps in three ways. Firstly, SREs can investigate current and historical data related to the usage of IT resources like memory, disk space, CPU, and network bandwidth. This data showcases trends that can be useful for making future analysis. Secondly, based on the forecasted trends, SREs can plan to size resources like CPU, memory, network bandwidth, and disk space. Lastly, once the resource needs are determined, SREs can ensure they are readily available. This involves provisioning cloud resources & servers, upgrading hardware, and optimizing software to meet future needs more efficiently, helping SREs plan capacity.
Incidence response and continuous improvement: Observability tools are indispensable for Site Reliability Engineers (SREs) in effectively managing incidence and driving continuous improvement. When an incidence strikes, observability tools provide vital real-time data that helps SREs with the insights needed to respond promptly. This includes assessing the impact of the incidence, gauging user experience, and orchestrating a coordinated effort to resolve the issue swiftly. Beyond incidence response, observability fosters a culture of continuous improvement within SRE teams. With the help of historical data, SREs can detect recurring patterns and evolving trends. This refines the processes over time, ensuring that the shortcomings of the past do not repeat themselves. In this way, observability drives effective incidence management and continuous improvement for SRE teams.
Automation: SREs can achieve a high level of automation with observability data. Thanks to real-time data availability, SREs can automate collection, evaluation, and remediation based on alerts received from the system. This makes the SRE's job easy and boosts their productivity, enhancing their decision-making capability. Automation becomes the driving force in achieving reliability, efficiency, and incredible speed in their operations.
Challenges of implementing observability in SRE
1. Data overload:
Challenge: Dealing with the sheer volume of data generated by observability tools, especially in large-scale systems.
Tip: Implement effective data management and analysis strategies to extract meaningful insights without drowning in data.
2. Cost considerations:
Challenge: Implementing observability can be costly, primarily when investing in new tools or infrastructure.
Tip: Evaluate the cost of observability against the value it brings and ensure it justifies the investment.
3. Complexity in large-scale systems:
Challenge: Complexity arises when implementing observability in extensive systems with numerous components.
Tip: Carefully design and plan the observability strategy to ensure it remains effective and sustainable over time in large-scale environments.
4. Security and privacy concerns:
Challenge: Access to sensitive data for observability can raise security and privacy issues.
Tip: Establish robust security measures and comply with regulations to safeguard sensitive data while reaping the benefits of observability.
By acknowledging these challenges, teams can proactively address them and ensure a successful observability implementation. In conclusion, observability is a crucial aspect of SRE, offering substantial advantages, especially to teams managing large-scale software systems. By adhering to best practices and addressing potential challenges, SRE teams can use observability to support their objectives and enhance system reliability and efficiency.
Best practices for observability
Here are our golden tips for maintaining observability.
- Comprehensive data collection: Gather data from various system layers – networks, infrastructure, applications, and databases.
- Use diverse data collection methods: Utilize multiple data collection techniques like tracing, logging, and metrics for a holistic system view.
- Smart data storage: Employ both short-term and long-term storage for logs to facilitate prolonged issue identification and resolution.
- Standardized data formats: Adopt standardized data formats to enable seamless data sharing across different tools and systems.
- Real-time data analysis: Analyze data in real-time using tools like dashboards and alerts to detect and address issues as they arise.
- Prompt alert communication: Ensure timely alerts are delivered to the relevant individuals or teams when problems occur.
- Automation for efficiency: Automate tasks wherever possible to reduce the time and effort required for issue resolution.
Conclusion
Observability is a fundamental concept in site reliability engineering. They go hand in hand, serving as the cornerstone for maintaining high-performing, dependable software systems. As technology continues to evolve, embracing SRE practices and investing in robust observability tools will be crucial for organizations looking to thrive in the digital landscape. For assistance in implementing the perfect observability solution for your organization’s need, reach out to us at contact@opcito.com.



