














Posted By

The pandemic forced the world to discover new ways to deal with almost everything. It also changed the way we work. While we are all settled in "the new normal" - work from-home scenario, it has forced organizations to put extra effort into security aspects of the business. Most of these security threats have resulted from a lack of visibility into the nature of threats and security practices. According to Gartner, by 2025, 99% of the failures in cloud security will be because of errors at customers' side. This indicates that you need to be prepared for any mishap and have a contingency plan, no matter how robust products and services you create. A strong incident response plan in cloud environments is no longer an option, but it is necessary. It is better to be prepared with an incident response plan than to have rudely awoken after an incident encounter.
According to Statista, in 2020, 25 percent of organizations worldwide reported an average hourly downtime cost of between 301,000 and 400,000 U.S. dollars. This clearly demonstrates a need for organizations to mitigate risks and manage incidents quickly and effectively. But now the question arises - what is the reason behind this downtime? Significant downtimes can happen due to reasons such as cyber attacks, human errors, coding errors, etc. A robust incident response plan can help you rapidly restore affected systems. However, there are different considerations for incident response strategies for cloud-based systems and infrastructure because of the shared responsibility model.
It is imperative to have a reliable cloud incident response plan in place. A standard incident response plan is a well-documented & well-written process with six distinct phases that help IT professionals deal with incidents. Let's look at the six-step incident response process that provides a structured framework for security incidents
- Preparation: This phase can be referred to as the workhorse of your incident response strategy, which includes establishing an organizational security policy, performing a risk assessment, determining sensitive assets, defining critical security incidents to focus on, and building a team for security incident response.
- Identification: This phase exhibits the process of identifying a breach and the area of its origin. Monitor your systems to detect deviations in operations, identify actual security incidents, and investigate their severity & type.
- Containment: This phase helps you prepare for the aftermath of an incident. When a breach occurs, conserve shreds of evidence to stop further damage to your business. Have short-term and long-term containment strategies ready to prevent the spread of the threat and apply temporary fixes while rebuilding a clean system.
- Eradication: If traces of any malware or security issues remain in your systems, there are chances of reoccurrence or losing valuable data. Identify the root cause of the attack, remove malware to restore the affected systems, and take actions to stop similar attacks in the future.
- Recovery: This phase includes the process of restoring and returning the affected systems to normal operations. Test and monitor recovered systems and apply measures to prevent future attacks.
- Learn: This phase is all about learning from the experiences and findings. Perform a retrospective analysis of an incident with complete documentation to identify the type of breach, what worked best in your response plan, and determine how you can improve your incident response plan.
Best practices for incident response in the cloud
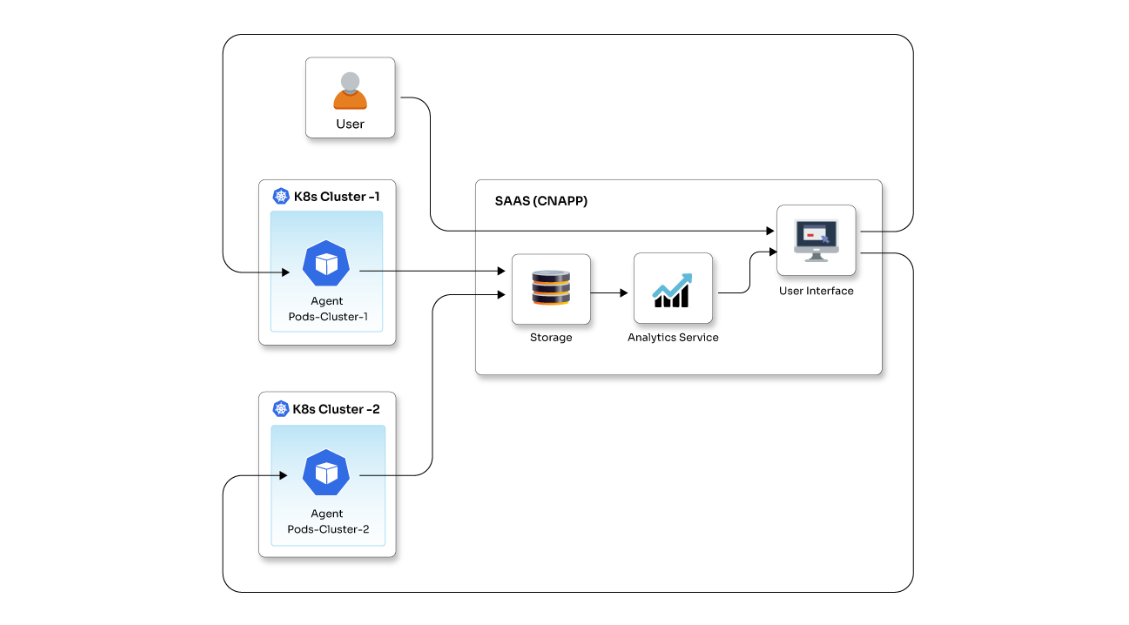
CloudOps has challenges such as an insufficient overview of information, inadequate design & roadmap, lack of visibility, and more. Thus, it is crucial to determine best practices in cloud incident handling. Let's have a look at some of the major ones.
- Establish response objectives: Security incidents or threats occur without any warning and can remain undetected for extended periods. It might become challenging for organizations to identify incidents as they often work in silos or because of the accrescent number of alerts. A proper incident response plan prepares your team to deal with incidents, identify their severity, isolate them, eradicate the underlying cause, and conduct a post-mortem to prevent potential attacks. However, don't jump on the bandwagon; consult with your stakeholders, legal advisors, and organizational leaders to determine incident response objectives for your organization.
- Use the cloud to respond: The incident response mechanism depends on your governance, risk, and compliance (GRC) model. Choose to respond to the incidents using the cloud, consulting with your legal counsel, leadership, business stakeholders, and others. You must ensure the availability of the required tools and resources to respond to an incident. Even though the cloud provides you with greater visibility and capabilities through APIs, the GRC model illustrates how to use those in your response strategy. Ensure to identify your Virtual Private Cloud (VPCs), corresponding network diagrams, logs, data locations, and data classifications so that you can set up cloud-based backup and recovery to investigate and remediate an incident rapidly.
- Determine your requirements: The collection and preservation of evidence are more likely to become difficult when confronted with multiple jurisdictions and systems. Organizations should prioritize what data can be extracted and requested and how to convert this data to a format that can be used in response mechanisms to restore affected systems rapidly. Many security events cannot be classified as incidents but still are prudent to be investigated. Organizations must preserve copies of logs, snapshots, and other evidence in a centralized cloud account. Use tags and metadata to maintain visibility and apply mechanisms to enforce retention policies.
- Use redeployment mechanisms: In the course of your investigation, if a security anomaly is attributed to a misconfiguration, it is easier to remediate by redeploying the resource with the appropriate configuration. To do this, you will require a plan ahead and your own security response procedures defined precisely. Organizations tend to gravitate toward different incident management procedures, so you need to determine the best fit according to your organizational requirements. Furthermore, ensure the response mechanisms are safe to be executed more than once.
- Leveraging automation: Automation acts as a force multiplier that scales the efforts of your organization to identify recurring incidents and automate as much as possible to build response mechanisms for everyday situations. If responders continue to respond to alerts manually, they risk alert fatigue. Over time, responders become desensitized to the warnings and miss unusual or critical signs while handling ordinary situations. Automation avoids fatigue by processing repetitive and mundane alerts, allowing responders to address unique, new, and critical incidents.
With the increasing numbers of cloud adopters, challenges & threats have also increased. Document everything, analyze the evidence, find the root cause, apply the response strategy, cleanse all the effects, and restore the operations to normal. Robust cloud incident response strategy coupled with customized policies as per the business needs is an absolute necessity. Get in touch with our experts to ensure your CloudOps with a robust cloud incident response strategy.


Related Blogs



